
Introduction
Duplicate User Detection is vital for ensuring data integrity and combating fraud in digital marketing. This filter identifies and blocks repeated clicks from the same user, enhancing tracking accuracy, reporting reliability, and optimizing ad spend.
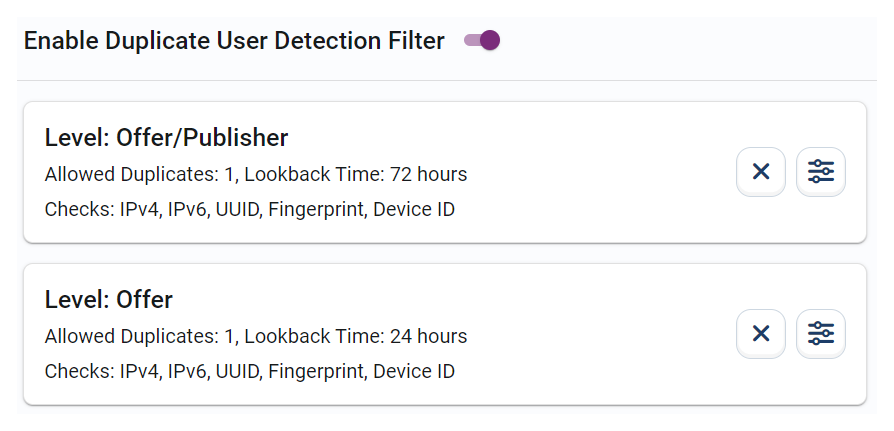
Key Features of Duplicate User Detection
Allowed Duplicates
Sets the maximum allowable clicks from a single user within a defined timeframe.
Lookback Time
Specifies the monitoring window for duplicate clicks, typically from minutes to hours.
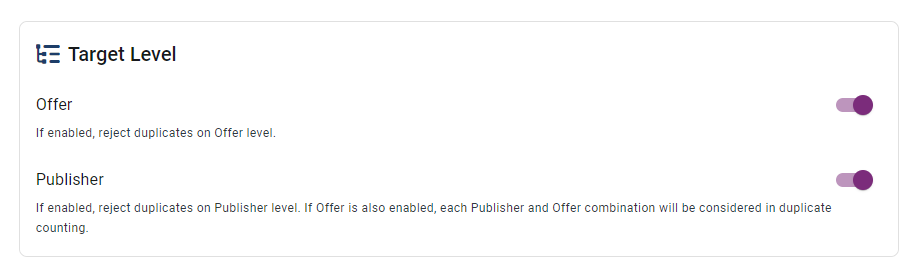
Detection Levels
- Offer Level: Limits duplicates for specific offers.
- Publisher Level: Controls duplicates across publishers.
Detection Mechanisms and Data Points
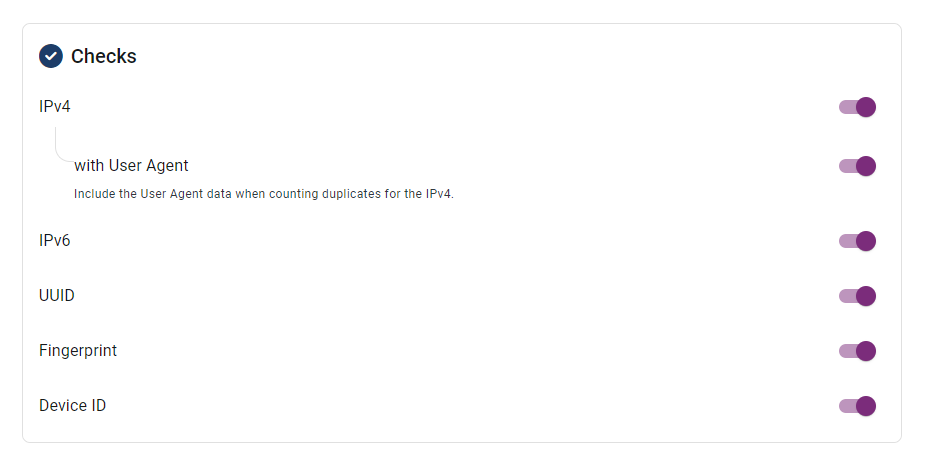
The system identifies duplicates using robust data points, including:
- IP Addresses: Tracks IPv4 and IPv6.
- UUIDs: Monitors unique user identifiers.
- Device IDs: Ensures clicks originate from distinct devices.
- User-Agent: Detects browser and OS details.
- Fingerprinting: Combines multiple data points into a unique identifier.
Configuration Rules
Customizable rules allow granular control over duplicate detection:
- Rule Creation: Tailored rules based on data points.
- Application Levels: Apply rules to offers or publishers.
Setting Up Duplicate User Detection
- Navigate to filter settings.
- Define allowed duplicates and lookback period.
- Select data points for detection, such as IP or UUID.
Conclusion
Duplicate User Detection is indispensable for digital marketing campaigns, particularly CPC models. By employing advanced detection mechanisms and configurable rules, businesses can ensure accurate data, combat fraud, and maximize ROI.